Anemone gemでのクロールメモ
Web サイトをクロールしたいことが出てきたので、 Anemone で行うのが基本なのだろうと思い、少し調べていました。
すると

Rubyによるクローラー開発技法 巡回・解析機能の実装と21の運用例
- 作者: 佐々木拓郎,るびきち
- 出版社/メーカー: SBクリエイティブ
- 発売日: 2014/08/23
- メディア: 単行本
- この商品を含むブログ (10件) を見る
元の本をちゃんと読んでないのですが、もしかするとこう書いてるのかな*1と思ったことを。
Anemone::Page#docはNokogiri::HTML::Documentオブジェクトだよ
クロールしたあとの Anemone::Page オブジェクトをスクレイピングする時に、例えばこう書いてありました(引用順は先ほどググった際に出てきた順なので特に意味はありません)。
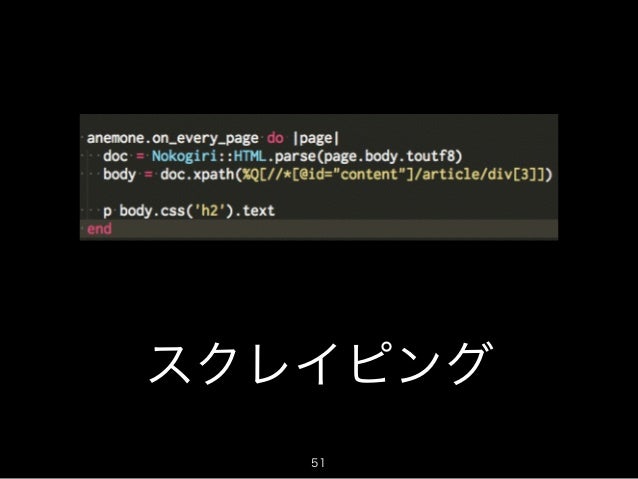
2. anemoneで取ってきたpageのHTMLデータをnokogiriオブジェクトに変換する
doc = Nokogiri::HTML.parse(page.body.toutf8)
Anemone.crawl(urls, :depth_limit => 0) do |anemone| anemone.on_every_page do |page| #文字コードをUTF8に変換したうえで、Nokogiriでパース doc = Nokogiri::HTML.parse(page.body.toutf8) : end end
★Nokogiriの文字コードについて
記述がありました。
構文解析を行うnokogiriは文字化けの可能性があり、対処法としては
Nokogiriに渡す前に文字コードを変換するか、Nokogiriに対して正しい文字コードを教えるかの2つの方法がある。
Anemoneには文字コードが組み込まれているが文字コードに対する対処の変更はできないので、Anemone内蔵のNokogiriとは別にNokogiriを定義して利用する必要がある。そんなわけで
require 'anemone' require 'nokogiri' require 'kconv' #日本語文字コード変換ライブラリとする。
さらに文字コードをUTF-8に変換したうえ、Nokogiriでパースしたオブジェクトを生成。(Anemone ve.0.7.2のAnemone::Page にパースしたオブジェクトを返すdocメソッドは文字コードがUTF-8以外の考慮がないから。)
▽Nokogiriの実装
def doc return @doc if @doc @doc = Nokogiri::HTML(@body) if @body && html? rescue nil enddoc = Nokogiri::HTML.parse(page.body.toutf8)
…ああ、なるほど4つ目に理由がちゃんと書いてあるね。
でもね、毎回そのままにするのはどうかと思うのよ。
元コードが UTF-8 になっていれば
doc = Nokogiri::HTML.parse(page.body.toutf8)
しなくても
doc = page.doc
Method: Anemone::Page#doc — Documentation for anemone (0.7.2)
で済むんだから*2。
もしくは4つ目での認識のように Anemone::Page クラスをオープンクラスで書き換えてやったらいいんじゃね?しかも kconv が必要な String#toutf8 じゃなくて String#encode で書くべきだと思うのよね(Ruby1.8時代じゃ無いんだから)。
module Anemone class Page # # Nokogiri document for the HTML body # def doc return @doc if @doc @doc = Nokogiri::HTML.parse(@body.encode('UTF-8')) if @body && html? rescue nil end end end
いや、それよりも大元からやり直すべきか。
module Anemone class Page # # Create a new page # def initialize(url, params = {}) @url = url @data = OpenStruct.new @code = params[:code] @headers = params[:headers] || {} @headers['content-type'] ||= [''] @aliases = Array(params[:aka]).compact @referer = params[:referer] @depth = params[:depth] || 0 @redirect_to = to_absolute(params[:redirect_to]) @response_time = params[:response_time] @body = params[:body].encode('UTF-8') @error = params[:error] @fetched = !params[:code].nil? end end end
このほうがいいな。
実際にやってみると String#encode ではうまくいかない… String#toutf8 ならば以下のようにして OK になる。
require 'kconv' module Anemone class Page # # Create a new page # def initialize(url, params = {}) @url = url @data = OpenStruct.new @code = params[:code] @headers = params[:headers] || {} @headers['content-type'] ||= [''] @aliases = Array(params[:aka]).compact @referer = params[:referer] @depth = params[:depth] || 0 @redirect_to = to_absolute(params[:redirect_to]) @response_time = params[:response_time] @body = params[:body].toutf8 if params[:body] @error = params[:error] @fetched = !params[:code].nil? end end end
Anemone::Core#on_pages_likeでリンクリストの正規表現マッチ限定出来るぞ(でも問題あり>_<)
Qiita でこういう記述を見つけた。かなり多くストックされてる。
Anemone.crawl('http://example.com/start_page.html') do |anemone| # クロールするごとに呼び出される anemone.focus_crawl do |page| # 条件に一致するリンクだけ残す # この `links` はanemoneが次にクロールする候補リスト page.links.keep_if { |link| link.to_s.match(/detail/) } end anemone.on_every_page do |page| something.about(page) end end
たしかに Anemone::Page#links が(より正確には Anemone::Page クラスのインスタンス変数 @links が)リンク先の配列であり、Anemone::Core#focus_crawl に渡したブロックでクロールを行うリンク先を指定するので、Array#keep_if を使って目的のリンクだけにして指定しちゃえば OK なのは間違いない。
page.links.keep_if { |link|
link.to_s.match(/detail/)
}
でもさ。
Anemone::Core#on_pages_like というメソッドがあるんだから、それを使うべきじゃね?簡潔になるよ?しかも引数には複数渡せるから、もっと複雑な条件もできるよ。
Anemone.crawl('http://example.com/start_page.html') do |anemone| anemone.on_pages_like(/detail/) do |page| something.about(page) end end
ですが…問題がありました。
- Anemone::Core#on_pages_like だと、全てのリンクをスクレイピングしてから正規表現にマッチするものに対してブロック処理を行う
- Anemone::Core#focus_crawl で(正規表現にマッチする)必要なリンクだけに限定し、Anemone::Core#on_every_page でスクレイピングする
つまり…処理速度が格段に違いますし、サーバアクセス回数も格段に違いますorz*3
anemoneって
あんまり上手く考えられてないような…
もうちょっといい gem が作られそうなものなのになあ(ひとごと
読み直した
Rubyによるクローラー開発技法 巡回・解析機能の実装と21の運用例
- 作者: 佐々木拓郎,るびきち
- 出版社/メーカー: SBクリエイティブ
- 発売日: 2014/08/23
- メディア: 単行本
- この商品を含むブログ (10件) を見る